


Kubernetes Overview
With the widespread adoption of containers among organizations, Kubernetes, the container-centric management software, has become a standard to deploy and operate containerized applications and is one of the most important parts of DevOps.
Originally developed at Google and released as open-source in 2014. Kubernetes builds on 15 years of running Google's containerized workloads and the valuable contributions from the open-source community. Inspired by Google’s internal cluster management system, Borg,
- What is Kubernetes? Write in your own words and why do we call it k8s?
Kubernetes (also known as k8s or “kube”) is an open-source container orchestration platform that automates many of the manual processes involved in deploying, managing, and scaling containerized applications.
K8s is an abbreviation of Kubernetes. Instead of using the entire word, you simply replace the ‘ubernete’ with the digit 8. Add an ‘s’ and done.
2.What are the benefits of using k8s?
Kubernetes is beneficial for your business productivity.
Kubernetes has Multi-cloud Capability.
It Is Cheaper Than Its Alternatives.
Kubernetes Runs Your Applications With Better Stability.
It's now easier than ever to roll out new software versions.
Kubernetes Is Open Source And Free.
Kubernetes Is Portable And Flexible
Kubernetes Has Benefits of Cloud Native Management Tools For Free
Availability Of Resources Online
Access To Self-Healing Systems
Horizontal Scaling
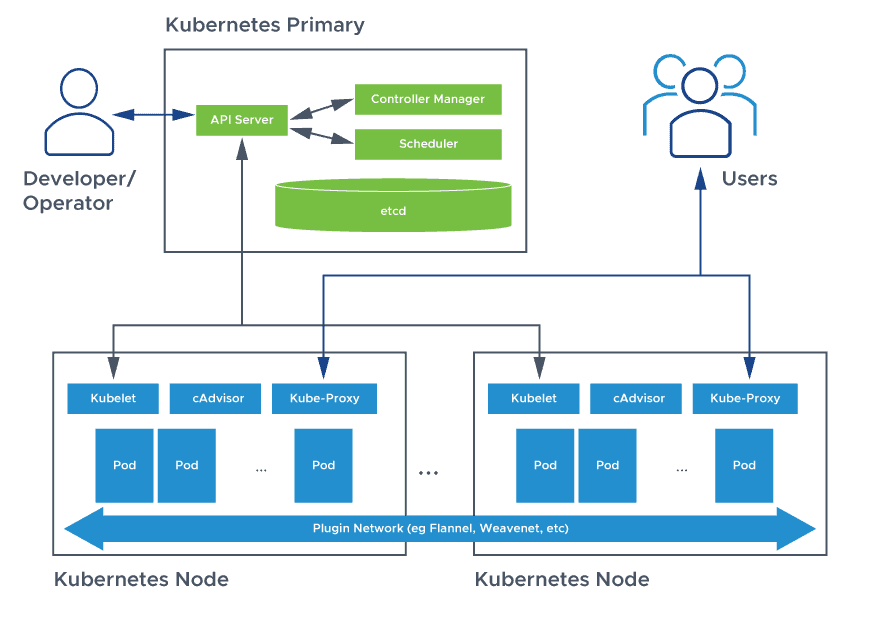
Explain the architecture of Kubernetes

Control Plane
The control plane is responsible for container orchestration and maintaining the desired state of the cluster. It has the following components.
kube-apiserver
etcd
kube-scheduler
kube-controller-manager
cloud-controller-manager
Worker Node
The Worker nodes are responsible for running containerized applications. The worker Node has the following components.
kubelet
kube-proxy
Container runtime
Kubernetes Control Plane Components
First, let’s take a look at each control plane component and the important concepts behind each component.
1. kube-apiserver
The kube-api server is the central hub of the Kubernetes cluster that exposes the Kubernetes API.
End users, and other cluster components, talk to the cluster via the API server. Very rarely monitoring systems and third-party services may talk to API servers to interact with the cluster.
So when you use kubectl to manage the cluster, at the backend you are actually communicating with the API server through HTTP REST APIs. However, the internal cluster components like the scheduler, controller, etc talk to the API server using gRPC.
The communication between the API server and other components in the cluster happens over TLS to prevent unauthorized access to the cluster.
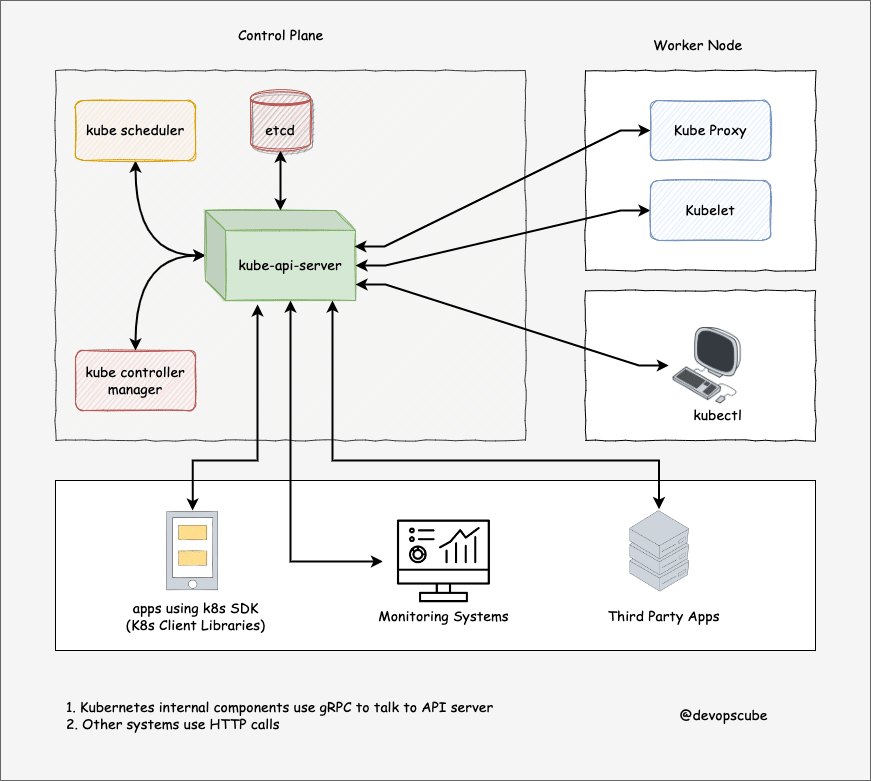
Kubernetes api-server is responsible for the following
API management: Exposes the cluster API endpoint and handles all API requests.
Authentication (Using client certificates, bearer tokens, and HTTP Basic Authentication) and Authorization (ABAC and RBAC evaluation)
Processing API requests and validating data for the API objects like pods, services, etc. (Validation and Mutation Admission controllers)
It is the only component that communicates with etcd.
api-server coordinates all the processes between the control plane and worker node components.
api-server has a built-in bastion apiserver proxy. It is part of the API server process. It is primarily used to enable access to ClusterIP services from outside the cluster, even though these services are typically only reachable within the cluster itself.
Note: To reduce the cluster attack surface, it is crucial to secure the API server. The Shadowserver Foundation has conducted an experiment that discovered 380 000 publicly accessible Kubernetes API servers.
2. etcd
Kubernetes is a distributed system and it needs an efficient distributed database like etcd that supports its distributed nature. It acts as both a backend service discovery and a database. You can call it the brain of the Kubernetes cluster.
etcd is an open-source strongly consistent, distributed key-value store. So what does it mean?
Strongly consistent: If an update is made to a node, strong consistency will ensure it gets updated to all the other nodes in the cluster immediately. Also if you look at CAP theorem, achieving 100% availability with strong consistency and & Partition Tolerance is impossible.
Distributed: etcd is designed to run on multiple nodes as a cluster without sacrificing consistency.
Key Value Store: A nonrelational database that stores data as keys and values. It also exposes a key-value API. The datastore is built on top of BboltDB which is a fork of BoltDB.
etcd uses raft consensus algorithm for strong consistency and availability. It works in a leader-member fashion for high availability and to withstand node failures.
So how etcd works with Kubernetes?
To put it simply, when you use kubectl to get kubernetes object details, you are getting it from etcd. Also, when you deploy an object like a pod, an entry gets created in etcd.
In a nutshell, here is what you need to know about etcd.
etcd stores all configurations, states, and metadata of Kubernetes objects (pods, secrets, daemonsets, deployments, configmaps, statefulsets, etc).
etcdallows a client to subscribe to events usingWatch()API . Kubernetes api-server uses the etcd’s watch functionality to track the change in the state of an object.etcd exposes key-value API using gRPC. Also, the gRPC gateway is a RESTful proxy that translates all the HTTP API calls into gRPC messages. It makes it an ideal database for Kubernetes.
etcd stores all objects under the /registry directory key in key-value format. For example, information on a pod named Nginx in the default namespace can be found under /registry/pods/default/nginx
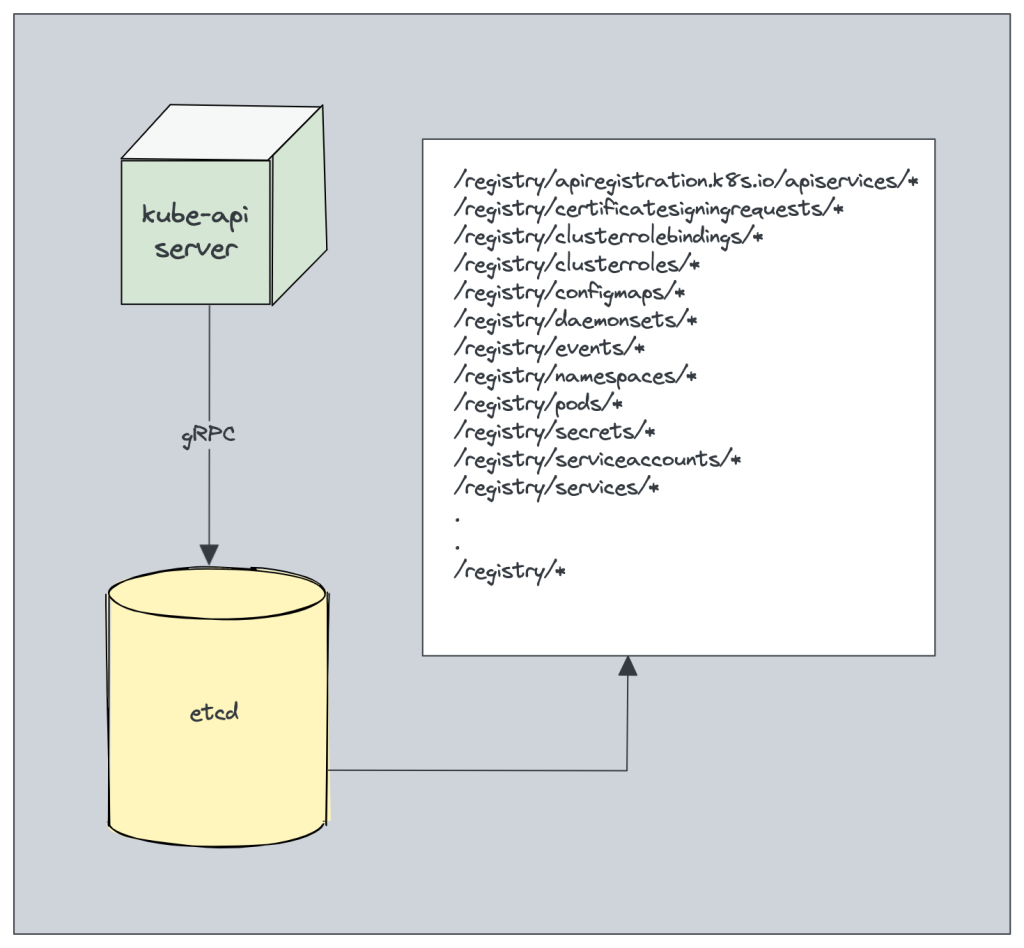
Also, etcd it is the only Statefulset component in the control plane.
3. kube-scheduler
The kube-scheduler is responsible for scheduling pods on worker nodes.
When you deploy a pod, you specify the pod requirements such as CPU, memory, affinity, taints or tolerations, priority, persistent volumes (PV), etc. The scheduler’s primary task is to identify the create request and choose the best node for a pod that satisfies the requirements.
The following image shows a high-level overview of how the scheduler works.

Here is how the scheduler works.
To choose the best node, the Kube-scheduler uses filtering and scoring operations.
In filtering, the scheduler finds the best-suited nodes where the pod can be scheduled. For example, if there are five worker nodes with resource availability to run the pod, it selects all five nodes. If there are no nodes, then the pod is unschedulable and moved to the scheduling queue. If It is a large cluster, let’s say 100 worker nodes, and the scheduler doesn’t iterate over all the nodes. There is a scheduler configuration parameter called
percentageOfNodesToScore. The default value is typically 50%. So it tries to iterate over 50% of nodes in a round-robin fashion. If the worker nodes are spread across multiple zones, then the scheduler iterates over nodes in different zones. For very large clusters the defaultpercentageOfNodesToScoreis 5%.In the scoring phase, the scheduler ranks the nodes by assigning a score to the filtered worker nodes. The scheduler makes the scoring by calling multiple scheduling plugins. Finally, the worker node with the highest rank will be selected for scheduling the pod. If all the nodes have the same rank, a node will be selected at random.
Once the node is selected, the scheduler creates a binding event in the API server. Meaning an event to bind a pod and node
4. Kube Controller Manager
What is a controller? Controllers are programs that run infinite control loops. Meaning it runs continuously and watches the actual and desired state of objects. If there is a difference in the actual and desired state, it ensures that the kubernetes resource/object is in the desired state.
Kube controller manager is a component that manages all the Kubernetes controllers. Kubernetes resources/objects like pods, namespaces, jobs, replicaset are managed by respective controllers. Also, the kube scheduler is also a controller managed by Kube controller manager.
The control plane manages the worker nodes and the Pods in the cluster.
Write the difference between kubectl and kubelets.
kubectl is the command-line interface (CLI) tool for working with a Kubernetes cluster. Kubelet is the technology that applies, creates, updates, and destroys containers on a Kubernetes node
Explain the role of the API server.
An API is also an abstraction of the web server. The application (such as a website or a mobile app) will make an API call for a set of data to display for the end user to consume. The request is made via the API that accesses the web server to retrieve the requested data, which is populated in the user interface.